An Amazon Web Services (AWS) Project (AWS Step Functions, AWS Lambda, AWS S3, Python)
This project had a dual purpose: building an automated stock valuation system and gaining hands-on experience with deploying a serverless application using Amazon Web Services (AWS).
Check the project result here:
https://stock-analysis-files.s3.eu-north-1.amazonaws.com/index.html
1. Stock Valuation
The primary goal was to automate the process of analyzing stock market data to calculate and rank stock valuations. The stock market is a complex ecosystem with numerous factors influencing stock prices, making it crucial for investors to have tools that can quickly assess which stocks are undervalued or overvalued. This project aimed to simplify that by collecting data on various stocks, calculating their valuation based on key metrics, and ranking them. By breaking the stocks down by sector and creating a “top 10” list for each, the tool provides a clear snapshot of which stocks are performing well across different sectors.
2. AWS Deployment
The second objective was to experiment with deploying a scalable, serverless application using AWS. AWS provides a suite of tools that enable developers to create applications without managing servers, making it an ideal platform for this project. I wanted to explore the benefits and challenges of using AWS Lambda, Step Functions, and S3 for orchestrating tasks, handling data, and optimizing cost. The deployment process also provided an opportunity to understand AWS’s pay-per-use pricing model and how to architect solutions that scale efficiently without incurring high costs.
By combining these two goals, the project not only provided valuable insights into stock analysis but also served as a learning experience in modern cloud infrastructure, particularly serverless computing on AWS.
Requirements
This section outlines both the functional and characteristic requirements of the stock valuation project, which was designed to automate the collection, analysis, and ranking of stocks listed on the New York Stock Exchange (NYSE).
1. Functional Requirements
The project’s functionality revolves around four main tasks:
- Data Collection: The system must collect data on all stocks listed on the NYSE, which includes approximately 5,000 stocks. This data should be retrieved from an external stock market API and include key financial metrics (e.g., stock price, market capitalization, and volume).
- Stock Valuation Calculation: For each stock, the system must perform valuation calculations based on specific financial metrics. The valuation model might include ratios like Price-to-Earnings (P/E), Price-to-Book (P/B), or other custom formulas that help assess the stock’s value.
- Sorting and Reporting: Once valuations are calculated, the system must:
- Sort the stocks based on their valuation metrics.
- Identify the top 10 performing stocks across each sector (e.g., technology, healthcare, finance).
- Generate an overall top 10 list regardless of sector.
- Output HTML Report: The final sorted results should be presented in a human-readable format. The output should be written to an HTML page, containing the top 10 stocks by sector and the overall top 10 list. This report must be updated once a week.
2. Characteristic Requirements
- Scale: The system must handle data for approximately 5,000 stocks. This means the workflow, including Lambda functions and data storage, should be optimized for both performance and cost-efficiency to process and analyze such a large volume of stocks.
- Frequency: The project must be executed once a week. This requires an automated scheduling mechanism (e.g., using AWS CloudWatch Events or Step Functions) to trigger the entire process, ensuring that the stock data is refreshed and analyzed at the start of each week. I skip this automated trigger in the first version of the project and instead I rely on manual start of execution of this system.
- Reliability: Since the system processes a large number of stocks, it needs to handle potential failures (e.g., network or API outages) gracefully. Appropriate error-handling mechanisms must be in place to retry failed API calls or process partial data without impacting the final output.
By fulfilling these functional and characteristic requirements, the project ensures accurate, scalable, and timely stock valuations, helping investors track top-performing stocks in different sectors on a weekly basis.
Constraints
The project faced several important constraints that influenced its design and implementation, particularly in the areas of external API usage, cost management, and AWS service limitations.
1. API Rate Limit
The external stock market API used for fetching data imposes a rate limit on the number of requests that can be made within a specific time frame. With approximately 5,000 stocks listed on the NYSE, this constraint made it challenging to collect data for all stocks without exceeding the API’s limits.
2. Cost
Running the project using AWS services incurs costs based on the number of Lambda function invocations, S3 storage, and data transfer operations. Additionally, the cost of API requests, especially when retrieving large datasets on a weekly basis, can add up over time, potentially affecting the overall project budget.
3. AWS S3 Read and Write Operations
The project uses AWS S3 for storing input and output data, including stock information and HTML reports. Each read and write operation to S3 is subject to AWS pricing, and with 5,000 stocks processed weekly, a high number of read and write operations could lead to increased costs.
4. Lambda Function Running Time
AWS Lambda functions have a maximum execution time of 15 minutes per invocation. Given the large volume of stock data to process, certain tasks, such as valuation calculations and sorting operations, run the risk of exceeding this time limit, which could disrupt the workflow.
System Design
The stock valuation system was built using a serverless architecture, leveraging multiple AWS services to automate the workflow. The design focuses on scalability, cost-efficiency, and the ability to process large volumes of stock data on a weekly basis. This section outlines the key components of the architecture, how they interact, and how data flows through the system.
1. Architecture Overview
The system is designed around AWS Lambda and AWS Step Functions, with S3 serving as the data storage layer. The key components of the architecture are:
- AWS Lambda Functions: Lambda functions are responsible for individual tasks such as fetching stock data, calculating stock valuations, sorting stocks by sector, and generating HTML reports. Each Lambda function performs a specific part of the process in a stateless manner.
- AWS Step Functions: Step Functions are used to orchestrate the execution of the Lambda functions. The workflow begins with data collection, proceeds through valuation and sorting, and ends with generating the final HTML report. Step Functions manage the flow of data between Lambda functions, handle errors, and ensure that each step completes before moving to the next.
- AWS S3: S3 is used to store both the input and output data. Stock data fetched from the API is temporarily stored in S3 for processing by the Lambda functions. The final report, which ranks the top 10 stocks per sector and overall, is also written to S3 in the form of an HTML file.
- External API: The system retrieves stock data from an external API (such as Alpha Vantage or Yahoo Finance). The API provides real-time and historical stock market data for the approximately 5,000 stocks listed on the NYSE.
2. Data Flow
The data flow through the system occurs in a series of steps, each orchestrated by AWS Step Functions:
- Step 1: Data Collection
- A Lambda function is triggered at the start of each week, which requests stock data from the external API. The data includes key financial metrics for each stock. The results are written to S3 in batches, typically in JSON format.
- Step 2: Stock Valuation Calculation
- Another Lambda function retrieves the stock data from S3, calculates the valuation for each stock based on predefined financial formulas, and stores the results back in S3.
- Step 3: Sorting and Ranking
- A third Lambda function reads the calculated valuations from S3, sorts the stocks by sector, and identifies the top 10 performing stocks in each sector. Additionally, the top 10 stocks overall (across all sectors) are determined and stored in a temporary location in S3.
- Step 4: Report Generation
- The final Lambda function generates an HTML report displaying the top 10 stocks per sector and the overall top 10 list. This HTML report is saved to S3 and can be viewed or downloaded by users.
3. Interfaces
The system interfaces with several external and internal services:
- External Stock Market API: Used to collect stock data, including real-time prices and financial metrics.
- AWS Step Functions: Orchestrates Lambda functions, manages state transitions, and ensures that the workflow is completed in the correct order.
- AWS S3: Acts as the data storage layer, facilitating data transfer between different Lambda functions and storing final outputs.
4. Data Model and Transfer
- Input Data: The input data consists of stock metrics such as price, volume, and financial ratios (e.g., P/E ratio), retrieved from the external API. This data is typically stored in JSON format within S3.
- Intermediate Data: During processing, intermediate results such as stock valuations and sorted lists are stored in S3, making it possible to reprocess individual steps without re-running the entire workflow.
- Output Data: The final output is an HTML report that lists the top 10 stocks by sector and the overall top 10 stocks. This report is stored in S3 and updated weekly.
5. Scheduling and Automation
The entire system is designed to run automatically once a week. Scheduling is handled using AWS CloudWatch Events, which trigger the Step Functions workflow every week. This ensures that the stock data, calculations, and report generation happen on a consistent schedule without requiring manual intervention.
Implementation
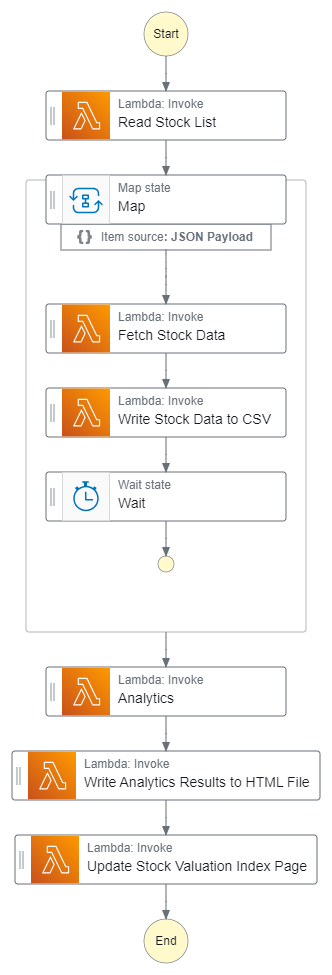
Challenges
During the development and deployment of the stock valuation system, several challenges emerged that tested the robustness and efficiency of the design. Two significant challenges included testing individual Lambda functions versus the entire Step Functions workflow, as well as dealing with inherent limitations of Lambda functions themselves.
1. Individual Lambda Function Test versus Step Functions Test
One of the primary challenges encountered was the difference in testing individual Lambda functions compared to testing the integrated Step Functions workflow.
- Isolation Testing: Testing Lambda functions in isolation was relatively straightforward. Each function could be executed independently with controlled inputs, allowing for focused debugging and validation of specific tasks, such as data collection or valuation calculations.
- Integration Testing: However, when the system was tested as a whole using Step Functions, issues arose that were not apparent during individual testing. The flow of data between functions, timing issues, and error handling became more complex. For instance, if one Lambda function failed or returned unexpected results, it could cause downstream functions to behave incorrectly. Identifying the source of these issues required comprehensive logging and monitoring to trace the data flow and state transitions throughout the workflow.
- Complex Dependencies: The dependencies between Lambda functions added another layer of complexity. Ensuring that each function received the correct input from the previous step and handled any potential errors gracefully was critical to maintaining the overall integrity of the system.
- Python Lambda Function Dependencies: One of the challenges faced when deploying Python Lambda functions was the dependency limitations, especially with large libraries like pandas. AWS Lambda has a maximum deployment package size, and libraries such as pandas, which are essential for data manipulation and analysis, can easily exceed this limit when combined with other dependencies. Additionally, Lambda requires all dependencies to be packaged and uploaded along with the function code, making it inefficient to include large libraries directly in the function package. To solve this, AWS offers Lambda Layers, which allows you to store libraries separately and reuse them across multiple functions. However, even when using Layers, certain packages, like pandas, that have C-based dependencies require special handling, as they need to be built in a Linux environment to ensure compatibility with the Lambda execution environment.To handle this issue, I had to use Docker to create the Lambda Layer. Since AWS Lambda runs on an Amazon Linux environment, I needed to ensure that the version of pandas (and its dependencies) was compiled in a compatible Linux environment. Docker allowed me to simulate this environment locally by using an Amazon Linux container. Inside the container, I installed pandas and all necessary libraries, packaged them into a ZIP file, and uploaded this ZIP as an AWS Lambda Layer. This process allowed me to bypass the size limitations of Lambda deployment packages while ensuring that the dependencies worked correctly in the AWS Lambda runtime. Although this approach worked, it introduced extra steps in the development workflow, requiring knowledge of Docker and additional time for packaging and testing the layer.
2. Lambda Function Limitations
AWS Lambda functions, while powerful and convenient, come with certain limitations that impacted the development and execution of the project:
- Execution Time Limit: Each Lambda function has a maximum execution time of 15 minutes. For tasks that required processing large datasets or performing complex calculations (like sorting and ranking thousands of stocks), this time constraint posed a challenge. Functions that approached this limit risked timing out, leading to incomplete processing and potential data loss.
- Memory Constraints: Lambda functions are also limited by the amount of memory allocated to them, which can affect performance. Operations requiring substantial memory (such as handling large datasets or performing heavy computations) could result in slower execution times or even function failures if the allocated memory was insufficient.
- Cold Start Latency: When a Lambda function is invoked after a period of inactivity, it experiences a “cold start,” which introduces additional latency. This can be particularly problematic for workflows that rely on quick responses or need to process data in real time. Managing cold starts was essential to optimize the overall performance of the system.
- Statelessness: Lambda functions are inherently stateless, which means they do not retain data between invocations. This necessitated careful handling of data transfer and state management throughout the workflow, requiring additional logic to ensure that intermediate results were stored in S3 before moving on to subsequent processing steps.
These challenges highlighted the importance of thorough testing, careful planning, and optimization of the serverless architecture to ensure a reliable and efficient stock valuation system.
Learned Lessons
Reflecting on the development and deployment of the stock valuation system, several key lessons emerged that can guide future projects in similar domains. These lessons emphasize the importance of planning and design in building robust, scalable systems.
1. Design Interfaces First
One of the critical lessons learned was the importance of designing interfaces before diving into implementation. By clearly defining the interactions between components, such as Lambda functions and external APIs, I was able to establish a solid foundation for the workflow. This approach facilitated better communication between teams and reduced the likelihood of integration issues later on. It also allowed for more efficient debugging, as I could pinpoint issues in specific interfaces rather than sifting through complex logic.
2. Design Data Model, Transfer, and Storage
Another valuable lesson was the significance of thoroughly designing the data model, including how data is transferred and stored. A well-defined data model helps ensure that all components of the system can effectively communicate and process data consistently. I learned that:
- Data Structure: Establishing a clear structure for how stock data is formatted (e.g., JSON) made it easier to manipulate and analyze within the Lambda functions.
- Storage Strategy: Planning for how data would be stored in S3, including considerations for file formats and organization, was crucial for optimizing read/write operations and minimizing costs. This foresight improved the efficiency of data retrieval during processing.
- Data Transfer: Thinking through how data flows between Lambda functions and external APIs helped avoid bottlenecks and ensured that all components had access to the necessary information at the right time.
3. Think About Testing Ahead
Lastly, I learned the importance of considering testing strategies early in the development process. Effective testing is essential for maintaining system reliability and performance, especially in a complex workflow involving multiple components. By planning for testing upfront:
- Comprehensive Test Cases: I was able to create detailed test cases for both individual Lambda functions and the integrated workflow, ensuring that all possible scenarios were accounted for.
- Monitoring and Logging: Implementing robust logging from the beginning made it easier to track data flow and identify issues during testing and production. This proactive approach facilitated quicker diagnosis of problems when they arose.
- Iterative Testing: Establishing a cycle of iterative testing throughout the development process helped identify and resolve issues sooner, reducing the overall time spent on debugging after deployment.
These lessons learned not only enhanced the effectiveness of this project but will also serve as guiding principles for future endeavors in serverless architecture and data processing.
Future Enhancements
As the stock valuation system continues to evolve, several enhancements are planned to extend its functionality, improve its analytical capabilities, and scale its deployment infrastructure.
1. Expanding Stock Coverage
One of the most significant future extensions involves expanding the scope of the project to include stocks from other global exchanges, such as the NASDAQ, London Stock Exchange (LSE), and Tokyo Stock Exchange (TSE). In addition, there are plans to integrate derivative instruments like options and futures, allowing for a more comprehensive analysis of both equity and derivative markets. This would provide users with a broader range of investment opportunities and deeper insights into market trends.
2. Enhanced Data Analysis and Visualizations
The project can be expanded to offer richer data visualizations and analysis. Currently, the output is limited to a ranked list of top-performing stocks, but future updates could include more dynamic visual representations, such as interactive charts showing historical performance, sector-wise comparisons, and portfolio optimization metrics. Furthermore, incorporating macroeconomic data, such as interest rates, inflation, and money supply (M2), would add valuable context to the stock valuations, helping users understand how broader economic factors influence market performance. The system could analyze the potential impact of these variables and integrate them into the stock-picking process.
Additionally, a weekly published report could be generated that includes not only the top 10 stocks but also a detailed analysis of the selected stocks, discussing market trends, sector performance, and potential risks. This report could also feature commentary on relevant macroeconomic data, offering insights into how factors like interest rates or inflation might impact the stock market in the upcoming week.
3. Deployment Enhancements
As the project scales, there are several deployment improvements to consider. Currently, the system relies on a serverless architecture using AWS Lambda, but for larger datasets or more complex computations (like those required for derivatives), it may be beneficial to explore deployment on EC2 instances or using containerized environments such as AWS Fargate or ECS (Elastic Container Service). This would provide more control over the execution environment, allow for greater memory and processing power, and make it easier to handle longer-running tasks without worrying about Lambda’s time and memory limitations.
By deploying the system on EC2 or containers, the infrastructure could also be more easily scaled horizontally, making it possible to run parallel computations on a larger number of stocks or derivative instruments. Additionally, using container orchestration tools like Kubernetes would enable efficient resource management and scaling as the project expands to cover more exchanges and asset classes.